This vignette presents three examples of using
slowrake() to find keywords in text. Each application runs
RAKE on a different type of document, including a webpage, patent
abstract(s), and a journal article.
Webpage
1. Download the HTML and run RAKE
# Load the libraries needed for all three applications
library(slowraker)
library(httr)
library(xml2)
library(patentsview)
library(dplyr)
library(pdftools)
library(stringr)
library(knitr)
# The webpage of interest - slowraker's "Getting started" page
url <- "https://crew102.github.io/slowraker/articles/getting-started.html"
GET(url) %>%
content("text") %>%
read_html() %>%
xml_find_all(".//p") %>%
xml_text() %>%
paste(collapse = " ") %>%
iconv(from = "UTF-8", "ASCII", sub = '"') %>%
slowrake() %>%
.[[1]]
#> keyword freq score stem
#> 1 rapid automatic keyword extraction 1 13.5 rapid automat keyword extract
#> 2 minimal lexical meaning 1 9.0 minim lexic mean
#> 3 member word scores 1 5.4 member word score
#> 4 christopher baker 1 4.0 christoph baker
#> 5 completely unsupervised 1 4.0 complet unsupervis
#> 6 essential idea 1 4.0 essenti idea
#> 7 main steps 1 4.0 main step
#> 8 original version 1 4.0 origin version
#> 9 potential delimiter 1 4.0 potenti delimit
#> 10 punctuation character 1 4.0 punctuat charact
#> 11 standard punctuation 1 4.0 standard punctuat
#> 12 member word 2 3.9 member word
#> 13 phrase delimiter 2 3.8 phrase delimit
#> 14 phrase delimiters 3 3.8 phrase delimit
#> 15 contiguous words 1 3.6 contigu word
#> 16 function words 1 3.6 function word
#> 17 multiple words 1 3.6 multipl word
#> 18 stop word 1 3.6 stop word
#> 19 stop words 3 3.6 stop word
#> 20 candidate keyword 1 3.5 candid keyword
#> 21 candidate keywords 3 3.5 candid keyword
#> 22 keywords frequently 1 3.5 keyword frequent
#> 23 dog leash 1 3.5 dog leash
#> 24 total number 1 3.5 total number
#> 25 treat verbs 1 3.5 treat verb
#> 26 phrase 1 1.8 phrase
#> 27 word 6 1.6 word
#> 28 words 2 1.6 word
#> 29 keyword 3 1.5 keyword
#> 30 keywordness 1 1.5 keyword
#> 31 keywords 5 1.5 keyword
#> 32 dog 1 1.5 dog
#> 33 number 1 1.5 number
#> 34 score 3 1.5 score
#> 35 verbs 1 1.5 verb
#> 36 addition 1 1.0 addit
#> 37 algorithm 2 1.0 algorithm
#> 38 authors 1 1.0 author
#> 39 beginning 1 1.0 begin
#> 40 comma 1 1.0 comma
#> 41 degree 3 1.0 degre
#> 42 details 1 1.0 detail
#> 43 developed 1 1.0 develop
#> 44 documents 1 1.0 document
#> 45 end 1 1.0 end
#> 46 equal 1 1.0 equal
#> 47 examples 1 1.0 exampl
#> 48 frequency 2 1.0 frequenc
#> 49 gram 1 1.0 gram
#> 50 observation 1 1.0 observ
#> 51 parameter 1 1.0 paramet
#> 52 parameters 1 1.0 paramet
#> 53 part 1 1.0 part
#> 54 parts 1 1.0 part
#> 55 period 1 1.0 period
#> 56 pkgdown 1 1.0 pkgdown
#> 57 pos 1 1.0 po
#> 58 quick 1 1.0 quick
#> 59 quickly 1 1.0 quickli
#> 60 rake 6 1.0 rake
#> 61 rarely 1 1.0 rare
#> 62 rose 2 1.0 rose
#> 63 set 1 1.0 set
#> 64 site 1 1.0 site
#> 65 slowrake 4 1.0 slowrak
#> 66 speech 2 1.0 speech
#> 67 sum 1 1.0 sum
#> 68 support 1 1.0 support
#> 69 technically 1 1.0 technic
#> 70 text 1 1.0 text
#> 71 times 2 1.0 time
#> 72 unique 1 1.0 uniquPatent abstracts
1. Download patent data
# Download data from the PatentsView API for 10 patents with the phrase
# "keyword extraction" in their abstracts
pv_data <- search_pv(
query = qry_funs$text_phrase(patent_abstract = "keyword extraction"),
fields = c("patent_number", "patent_title", "patent_abstract"),
per_page = 10
)
# Look at the data
patents <- pv_data$data$patents
kable(head(patents, n = 2))| patent_number | patent_title | patent_abstract |
|---|---|---|
| 10013574 | Method and apparatus for secure storage and retrieval of encrypted files in public cloud-computing platforms | In one aspect, a computerized Encrypted Drive System (EDS) server useful for keyword extraction and indexing server of includes a computer store containing data, wherein the data. The data includes an unencrypted document file and a computer processor in the EDS server. The computer processor obtains the unencrypted document file from the computer store. The computer processor extracts a keyword information from the unencrypted document file. The keyword information comprises of a set of keywords appearing in the unencrypted document file. The computer processor includes one or more colors from the color-set of each keyword into a document color-index of the unencrypted document file. The computer processor generates a Bloom filter encoding a set of keywords stored in a metadata field and the unencrypted document file, and wherein the Bloom filter is used to represent the set of keywords in the unencrypted document file. |
| 10049102 | Method and system for providing semantics based technical support | Disclosed is a system for providing semantics based technical support to a user. A keyword extraction module extracts a set of keywords from a plurality of knowledge content and a plurality of bug content. A matrix generation module generates a keyword-content matrix comprising a similarity score computed for each keyword corresponding to each knowledge content. The matrix generation module further decomposes the keyword-content matrix into one or more sub-matrices. A vector coordinates identification module determines a first set of vector coordinates for each knowledge content of the plurality of knowledge content and a second set of vector coordinates for a bug-query received from a user in real-time. A similarity measure module computes a cosine similarity measure of the bug-query with each knowledge content to identify at least one knowledge content relevant to the bug-query. The knowledge identification module further provides the at least one knowledge content to the user. |
2. Run RAKE on the abstracts
rakelist <- slowrake(
patents$patent_abstract,
stop_words = c("method", smart_words), # Consider "method" to be a stop word
stop_pos = pos_tags$tag[!grepl("^N", pos_tags$tag)] # Consider all non-nouns to be stop words
)
# Create a single data frame with all patents' keywords
out_rake <- rbind_rakelist(rakelist, doc_id = patents$patent_number)
out_rake#> doc_id keyword freq score
#> 1 10013574 encrypted drive system 1 9.0
#> 2 10013574 document color index 1 6.6
#> 3 10013574 indexing server 1 4.2
#> 4 10013574 document file 7 4.1
#> 5 10013574 bloom filter 2 4.0
#> 6 10013574 computer processor 5 4.0
#> 7 10013574 computer store 2 4.0
#> 8 10013574 metadata field 1 4.0
#> 9 10013574 keyword extraction 1 3.4
#> 10 10013574 keyword information 2 3.4
#> 11 10013574 color set 1 3.2
#> 12 10013574 eds server 1 3.2
#> 13 10013574 colors 1 2.0
#> 14 10013574 server 1 1.7
#> 15 10013574 eds 1 1.5
#> 16 10013574 keyword 1 1.4
#> 17 10013574 keywords 3 1.4
#> 18 10013574 set 3 1.2
#> 19 10013574 aspect 1 1.0
#> 20 10013574 data 3 1.0
#> 21 10049102 similarity measure module 1 7.6
#> 22 10049102 keyword extraction module 1 7.5
#> 23 10049102 knowledge identification module 1 7.4
#> 24 10049102 matrix generation module 1 7.0
#> 25 10049102 identification module 1 5.3
#> 26 10049102 similarity measure 1 4.8
#> 27 10049102 similarity score 1 4.3
#> 28 10049102 matrix generation 1 4.2
#> 29 10049102 knowledge content 7 4.1
#> 30 10049102 bug content 1 4.0
#> 31 10049102 bug query 3 4.0
#> 32 10049102 real time 1 4.0
#> 33 10049102 vector coordinates 2 3.7
#> 34 10049102 matrix 2 1.8
#> 35 10049102 keyword 1 1.7
#> 36 10049102 keywords 1 1.7
#> 37 10049102 vector 1 1.7
#> 38 10049102 matrices 1 1.0
#> 39 10049102 plurality 3 1.0
#> 40 10049102 semantics 1 1.0
#> 41 10049102 set 3 1.0
#> 42 10049102 support 1 1.0
#> 43 10049102 system 1 1.0
#> 44 10049102 user 3 1.0
#> 45 10255908 grasper grasps 1 4.0
#> 46 10255908 search result 1 4.0
#> 47 10255908 speech content 3 4.0
#> 48 10255908 voice data 3 4.0
#> 49 10255908 voice portion 1 4.0
#> 50 10255908 voice recognition 1 4.0
#> 51 10255908 indexing database 2 3.9
#> 52 10255908 indexing information 3 3.9
#> 53 10255908 indexing unit 1 3.9
#> 54 10255908 search word 3 3.8
#> 55 10255908 phoneme lattice 2 3.6
#> 56 10255908 keyword input 1 3.5
#> 57 10255908 phoneme string 1 3.1
#> 58 10255908 indexing 1 1.9
#> 59 10255908 word 1 1.8
#> 60 10255908 phoneme 2 1.6
#> 61 10255908 keyword 1 1.5
#> 62 10255908 string 1 1.5
#> 63 10255908 analysis 1 1.0
#> 64 10255908 comparison 1 1.0
#> 65 10255908 frame 2 1.0
#> 66 10255908 frames 1 1.0
#> 67 10255908 matching 1 1.0
#> 68 10255908 performs 1 1.0
#> 69 10255908 plurality 1 1.0
#> 70 10255908 reference 2 1.0
#> 71 10255908 searcher 2 1.0
#> 72 10255908 stores 1 1.0
#> 73 10255908 system 2 1.0
#> 74 10255908 time 2 1.0
#> 75 10255908 user 2 1.0
#> 76 10298654 keyword extraction 1 3.2
#> 77 10298654 keywords 4 1.2
#> 78 10298654 content 7 1.0
#> 79 10298654 context 1 1.0
#> 80 10298654 definitions 1 1.0
#> 81 10298654 meanings 1 1.0
#> 82 10298654 media 1 1.0
#> 83 10298654 portion 1 1.0
#> 84 10298654 portions 1 1.0
#> 85 10298654 resource 3 1.0
#> 86 10298654 techniques 1 1.0
#> 87 10298654 url 6 1.0
#> 88 10298654 urls 1 1.0
#> 89 10298654 user 1 1.0
#> 90 10298654 webpage 2 1.0
#> 91 10304441 grasper grasps 1 4.0
#> 92 10304441 search result 1 4.0
#> 93 10304441 speech content 3 4.0
#> 94 10304441 voice data 3 4.0
#> 95 10304441 voice portion 1 4.0
#> 96 10304441 voice recognition 1 4.0
#> 97 10304441 indexing database 2 3.9
#> 98 10304441 indexing information 3 3.9
#> 99 10304441 indexing unit 1 3.9
#> 100 10304441 search word 3 3.8
#> 101 10304441 phoneme lattice 2 3.6
#> 102 10304441 keyword input 1 3.5
#> 103 10304441 phoneme string 1 3.1
#> 104 10304441 indexing 1 1.9
#> 105 10304441 word 1 1.8
#> 106 10304441 phoneme 2 1.6
#> 107 10304441 keyword 1 1.5
#> 108 10304441 string 1 1.5
#> 109 10304441 analysis 1 1.0
#> 110 10304441 comparison 1 1.0
#> 111 10304441 frame 2 1.0
#> 112 10304441 frames 1 1.0
#> 113 10304441 matching 1 1.0
#> 114 10304441 performs 1 1.0
#> 115 10304441 plurality 1 1.0
#> 116 10304441 reference 2 1.0
#> 117 10304441 searcher 2 1.0
#> 118 10304441 stores 1 1.0
#> 119 10304441 system 2 1.0
#> 120 10304441 time 2 1.0
#> 121 10304441 user 2 1.0
#> 122 10311974 collecting patient chief complaint 1 13.4
#> 123 10311974 patient chief complaint 2 9.4
#> 124 10311974 phone device internet 1 9.0
#> 125 10311974 text word segmentation 1 9.0
#> 126 10311974 disease examination result 2 7.7
#> 127 10311974 disease examination 1 5.3
#> 128 10311974 diagnosis result 1 4.4
#> 129 10311974 guide result 2 4.2
#> 130 10311974 cloud server 1 4.0
#> 131 10311974 doctor information 1 4.0
#> 132 10311974 keyword extraction 1 4.0
#> 133 10311974 knowledge base 1 4.0
#> 134 10311974 recommendation technologies 1 4.0
#> 135 10311974 guide system 1 3.2
#> 136 10311974 patient 1 2.8
#> 137 10311974 guide 1 1.8
#> 138 10311974 system 1 1.5
#> 139 10311974 combination 1 1.0
#> 140 10311974 environment 1 1.0
#> 141 10311974 health 1 1.0
#> 142 10311974 invention 1 1.0
#> 143 10311974 matching 1 1.0
#> 144 10311974 optimum 1 1.0
#> 145 10311974 query 1 1.0
#> 146 10311974 terminal 2 1.0
#> 147 10311974 thereof 1 1.0
#> 148 10319020 product introduction support device 1 13.7
#> 149 10319020 display control information 1 9.0
#> 150 10319020 display control part 2 9.0
#> 151 10319020 group presentation part 2 8.7
#> 152 10319020 keyword extraction part 3 8.0
#> 153 10319020 word selection part 2 8.0
#> 154 10319020 product group 1 4.3
#> 155 10319020 keyword 2 2.0
#> 156 10319020 keywords 1 2.0
#> 157 10319020 word 2 2.0
#> 158 10319020 products 4 1.7
#> 159 10319020 attribute 1 1.0
#> 160 10319020 candidates 1 1.0
#> 161 10319020 plurality 4 1.0
#> 162 10319020 processing 1 1.0
#> 163 10319020 state 1 1.0
#> 164 10319020 web 1 1.0
#> 165 10387568 keyword extraction process 1 7.8
#> 166 10387568 input document 1 4.0
#> 167 10387568 match rate 1 4.0
#> 168 10387568 network page 1 4.0
#> 169 10387568 search engine 1 4.0
#> 170 10387568 search results 1 4.0
#> 171 10387568 candidate keyword 2 3.8
#> 172 10387568 candidate keywords 4 3.8
#> 173 10387568 keyword score 2 3.8
#> 174 10387568 keyword scores 1 3.8
#> 175 10387568 search terms 1 3.5
#> 176 10387568 keywords 3 1.8
#> 177 10387568 terms 1 1.5
#> 178 10387568 applications 1 1.0
#> 179 10387568 frequency 1 1.0
#> 180 10387568 length 1 1.0
#> 181 10387568 words 1 1.0
#> 182 10394864 cluster combination unit 1 7.4
#> 183 10394864 keyword extraction unit 1 6.9
#> 184 10394864 seed selection unit 1 6.9
#> 185 10394864 topic extraction server 1 6.8
#> 186 10394864 clustering unit 1 4.4
#> 187 10394864 document group 2 4.0
#> 188 10394864 topic group 1 3.8
#> 189 10394864 unit 1 2.4
#> 190 10394864 cluster 1 2.0
#> 191 10394864 server 1 2.0
#> 192 10394864 topic 2 1.8
#> 193 10394864 keyword 3 1.5
#> 194 10394864 seed 3 1.5
#> 195 10394864 noun 3 1.0
#> 196 10394864 sentence 1 1.0
#> 197 10394864 stopword 1 1.0
#> 198 10394864 suitability 1 1.0
#> 199 10394864 text 1 1.0
#> 200 10394864 times 1 1.0
#> 201 10394864 weight 2 1.0
#> 202 10477043 keyword extraction target 2 8.3
#> 203 10477043 target determination unit 3 8.2
#> 204 10477043 keyword extraction unit 2 8.1
#> 205 10477043 text reading unit 1 6.9
#> 206 10477043 image processing unit 3 6.8
#> 207 10477043 target 1 2.7
#> 208 10477043 keyword 1 2.6
#> 209 10477043 process 1 2.5
#> 210 10477043 unit 3 2.5
#> 211 10477043 image 5 1.8
#> 212 10477043 text 4 1.4
#> 213 10477043 apparatus 1 1.0
#> 214 10477043 document 1 1.0
#> stem
#> 1 encrypt drive system
#> 2 document color index
#> 3 index server
#> 4 document file
#> 5 bloom filter
#> 6 comput processor
#> 7 comput store
#> 8 metadata field
#> 9 keyword extract
#> 10 keyword inform
#> 11 color set
#> 12 ed server
#> 13 color
#> 14 server
#> 15 ed
#> 16 keyword
#> 17 keyword
#> 18 set
#> 19 aspect
#> 20 data
#> 21 similar measur modul
#> 22 keyword extract modul
#> 23 knowledg identif modul
#> 24 matrix gener modul
#> 25 identif modul
#> 26 similar measur
#> 27 similar score
#> 28 matrix gener
#> 29 knowledg content
#> 30 bug content
#> 31 bug queri
#> 32 real time
#> 33 vector coordin
#> 34 matrix
#> 35 keyword
#> 36 keyword
#> 37 vector
#> 38 matric
#> 39 plural
#> 40 semant
#> 41 set
#> 42 support
#> 43 system
#> 44 user
#> 45 grasper grasp
#> 46 search result
#> 47 speech content
#> 48 voic data
#> 49 voic portion
#> 50 voic recognit
#> 51 index databas
#> 52 index inform
#> 53 index unit
#> 54 search word
#> 55 phonem lattic
#> 56 keyword input
#> 57 phonem string
#> 58 index
#> 59 word
#> 60 phonem
#> 61 keyword
#> 62 string
#> 63 analysi
#> 64 comparison
#> 65 frame
#> 66 frame
#> 67 match
#> 68 perform
#> 69 plural
#> 70 refer
#> 71 searcher
#> 72 store
#> 73 system
#> 74 time
#> 75 user
#> 76 keyword extract
#> 77 keyword
#> 78 content
#> 79 context
#> 80 definit
#> 81 mean
#> 82 media
#> 83 portion
#> 84 portion
#> 85 resourc
#> 86 techniqu
#> 87 url
#> 88 url
#> 89 user
#> 90 webpag
#> 91 grasper grasp
#> 92 search result
#> 93 speech content
#> 94 voic data
#> 95 voic portion
#> 96 voic recognit
#> 97 index databas
#> 98 index inform
#> 99 index unit
#> 100 search word
#> 101 phonem lattic
#> 102 keyword input
#> 103 phonem string
#> 104 index
#> 105 word
#> 106 phonem
#> 107 keyword
#> 108 string
#> 109 analysi
#> 110 comparison
#> 111 frame
#> 112 frame
#> 113 match
#> 114 perform
#> 115 plural
#> 116 refer
#> 117 searcher
#> 118 store
#> 119 system
#> 120 time
#> 121 user
#> 122 collect patient chief complaint
#> 123 patient chief complaint
#> 124 phone devic internet
#> 125 text word segment
#> 126 diseas examin result
#> 127 diseas examin
#> 128 diagnosi result
#> 129 guid result
#> 130 cloud server
#> 131 doctor inform
#> 132 keyword extract
#> 133 knowledg base
#> 134 recommend technologi
#> 135 guid system
#> 136 patient
#> 137 guid
#> 138 system
#> 139 combin
#> 140 environ
#> 141 health
#> 142 invent
#> 143 match
#> 144 optimum
#> 145 queri
#> 146 termin
#> 147 thereof
#> 148 product introduct support devic
#> 149 displai control inform
#> 150 displai control part
#> 151 group present part
#> 152 keyword extract part
#> 153 word select part
#> 154 product group
#> 155 keyword
#> 156 keyword
#> 157 word
#> 158 product
#> 159 attribut
#> 160 candid
#> 161 plural
#> 162 process
#> 163 state
#> 164 web
#> 165 keyword extract process
#> 166 input document
#> 167 match rate
#> 168 network page
#> 169 search engin
#> 170 search result
#> 171 candid keyword
#> 172 candid keyword
#> 173 keyword score
#> 174 keyword score
#> 175 search term
#> 176 keyword
#> 177 term
#> 178 applic
#> 179 frequenc
#> 180 length
#> 181 word
#> 182 cluster combin unit
#> 183 keyword extract unit
#> 184 seed select unit
#> 185 topic extract server
#> 186 cluster unit
#> 187 document group
#> 188 topic group
#> 189 unit
#> 190 cluster
#> 191 server
#> 192 topic
#> 193 keyword
#> 194 seed
#> 195 noun
#> 196 sentenc
#> 197 stopword
#> 198 suitabl
#> 199 text
#> 200 time
#> 201 weight
#> 202 keyword extract target
#> 203 target determin unit
#> 204 keyword extract unit
#> 205 text read unit
#> 206 imag process unit
#> 207 target
#> 208 keyword
#> 209 process
#> 210 unit
#> 211 imag
#> 212 text
#> 213 apparatu
#> 214 document3. Show each patent’s top keyword
out_rake %>%
group_by(doc_id) %>%
arrange(desc(score)) %>%
slice(1) %>%
inner_join(patents, by = c("doc_id" = "patent_number")) %>%
rename(patent_number = doc_id, top_keyword = keyword) %>%
select(matches("number|title|keyword")) %>%
head() %>%
kable()| patent_number | top_keyword | patent_title |
|---|---|---|
| 10013574 | encrypted drive system | Method and apparatus for secure storage and retrieval of encrypted files in public cloud-computing platforms |
| 10049102 | similarity measure module | Method and system for providing semantics based technical support |
| 10255908 | grasper grasps | System for grasping keyword extraction based speech content on recorded voice data, indexing method using the system, and method for grasping speech content |
| 10298654 | keyword extraction | Automatic uniform resource locator construction |
| 10304441 | grasper grasps | System for grasping keyword extraction based speech content on recorded voice data, indexing method using the system, and method for grasping speech content |
| 10311974 | collecting patient chief complaint | Mobile health intelligent medical guide system and method thereof |
Journal article
1. Get PDF text
# The journal article of interest - Rose et. al (i.e., the RAKE publication)
url <- "http://media.wiley.com/product_data/excerpt/22/04707498/0470749822.pdf"
# Download file and pull out text layer from PDF
destfile <- tempfile()
GET(url, write_disk(destfile))
raw_txt <- pdf_text(destfile)2. Apply basic text cleaning
# Helper function for text removal
sub_all <- function(regex_vec, txt) {
pattern <- paste0(regex_vec, collapse = "|")
gsub(pattern, " ", txt)
}
txt1 <-
paste0(raw_txt, collapse = " ") %>%
gsub("\\r\\n", " ", .) %>%
gsub("[[:space:]]{2,}", " ", .)
# Regex to capture text that we don't want to run RAKE on
remove1 <- "Acknowledgements.*"
remove2 <- "TEXT MINING"
remove3 <- "AUTOMATIC KEYWORD EXTRACTION"
txt2 <- sub_all(c(remove1, remove2, remove3), txt1)3. Detect and remove tables
There are some sections of the PDF’s text that we don’t want to run RAKE on, such as the text found in tables. The problem with tables is that they usually don’t contain typical phrase delimiters (e.g., periods and commas). Instead, the cell of the table acts as a sort of delimiter. It can be very difficult to parse a table’s cells out in a PDF document, though, so we’ll just try to identify/remove the tables themselves.1
The tables in this article mostly contain numbers. If we split the article into text chunks using a digit delimiter, it’s likely that most of a table’s chunks will be relatively small in size. We can use this fact to help us identify which text chunks correspond to tables and which correspond to paragraphs.
# Numbers generally appear in paragraphs in two ways in this article: When the authors refer to results in a specific table/figure (e.g., "the sample abstract shown in Figure 1.1"), and when the authors reference another article (e.g., "Andrade and Valencia (1998) base their approach"). Remove these instances so that paragraphs don't get split into small chunks, which would make them hard to tell apart from tables.
remove4 <- "(Table|Figure) [[:digit:].]{1,}"
remove5 <- "\\([12][[:digit:]]{3}\\)"
txt3 <- sub_all(c(remove4, remove5), txt2)
# Split text into chunks based on digit delimiter
txt_chunks <- unlist(strsplit(txt3, "[[:digit:]]"))
# Use number of alpha chars found in a chunk as an indicator of its size
num_alpha <- str_count(txt_chunks, "[[:alpha:]]")
# Use kmeans to distinguish tables from paragraphs
clust <- kmeans(num_alpha, centers = 2)
good_clust <- which(max(clust$centers) == clust$centers)
# Only keep chunks that are thought to be paragraphs
good_chunks <- txt_chunks[clust$cluster == good_clust]
final_txt <- paste(good_chunks, collapse = " ")4. Run RAKE
| keyword | freq | score | stem |
|---|---|---|---|
| minimal set linear constraints linear constraints natural numbers strict inequations strict inequations nonstrict inequations nonstrict inequations upper bounds upper bounds | 1 | 115 | minim set linear constraint linear constraint natur number strict inequ strict inequ nonstrict inequ nonstrict inequ upper bound upper bound |
| algorithms equations numbers nonstrict systems minimal bounds system | 1 | 36 | algorithm equat number nonstrict system minim bound system |
| sets linear diophantine equations linear diophantine equations minimal | 1 | 34 | set linear diophantin equat linear diophantin equat minim |
| natural criteria upper linear strict sets | 1 | 29 | natur criteria upper linear strict set |
| extracted correct keywords keywords stoplist method size total | 1 | 28 | extract correct keyword keyword stoplist method size total |
| criteria compatibility system linear diophantine equations | 1 | 22 | criteria compat system linear diophantin equat |
5. Filter out bad keywords
The fact that some of the keywords shown above are very long suggests we missed something in Step 4. It turns out that our method mistook one of the tables (Table 1.1 shown below) for a paragraph. Table 1.1 is somewhat atypical in that it doesn’t contain any numbers, and thus it makes sense that our method missed it.
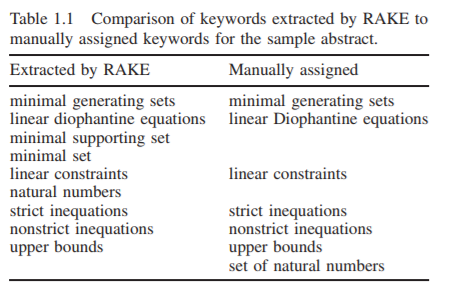
To clean up the results, let’s apply an ad hoc filter on the keywords. This filter will remove keywords whose long length indicates that a phrase run-on has occurred, and hence the keyword is no good.
# Function to remove keywords that occur only once and have more than max_word_cnt member words
filter.rakelist <- function(x, max_word_cnt = 3) {
structure(
lapply(x, function(r) {
word_cnt <- str_count(r$keyword, " ") + 1
to_filter <- r$freq == 1 & word_cnt > max_word_cnt
r[!to_filter, ]
}),
class = c("rakelist", "list")
)
}
filter <- function(x) UseMethod("filter")
filter(rakelist)[[1]]
#> keyword freq score stem
#> 10 upper bounds 1 16.0 upper bound
#> 11 diophantine inequations constraints 1 14.5 diophantin inequ constraint
#> 12 linear diophantine equations 2 13.7 linear diophantin equat
#> 15 natural numbers criteria 1 12.3 natur number criteria
#> 16 linear constraints 2 11.9 linear constraint
#> 20 nonstrict inequations 3 11.2 nonstrict inequ
#> 21 strict inequations 3 10.8 strict inequ
#> 25 minimal supporting set 1 10.1 minim support set
#> 26 minimal lexical meaning 1 9.6 minim lexic mean
#> 27 basic building block 1 9.0 basic build block
#> 28 greenhouse gas emissions 2 9.0 greenhous ga emiss
#> 30 machine learning algorithms 1 8.8 machin learn algorithm
#> 31 natural numbers 4 8.7 natur number
#> 32 specific grammar conventions 1 8.4 specif grammar convent
#> 33 inspec test set 1 7.8 inspec test set
#> 34 highly specific terminology 1 7.7 highli specif terminologi
#> 35 chi square measure 2 7.7 chi squar measur
#> 36 fine grained measurement 1 7.7 fine grain measur
#> 37 kyoto protocol legally 1 7.7 kyoto protocol legal
#> 38 top ranking words 1 7.7 top rank word
#> 39 natural language 1 7.4 natur languag
#> 40 language independent method 1 7.3 languag independ method
#> 41 stated conven tions 1 7.2 state conven tion
#> 42 shorter kyoto protocol 1 7.2 shorter kyoto protocol
#> 43 minimal set 1 7.1 minim set
#> 44 interior stop words 3 7.0 interior stop word
#> 45 fixed size 1 7.0 fix size
#> 46 keyword extraction method 1 7.0 keyword extract method
#> 47 mon function words 1 6.9 mon function word
#> 48 full text articles 1 6.8 full text articl
#> 49 keyword extraction research 1 6.8 keyword extract research
#> 50 additional analytic methods 1 6.7 addit analyt method
#> 51 content bearing words 1 6.7 content bear word
#> 52 corpus oriented methods 1 6.7 corpu orient method
#> 53 automatic keyword extraction 1 6.7 automat keyword extract
#> 54 document oriented methods 3 6.6 document orient method
#> 55 longer candidate keywords 2 6.5 longer candid keyword
#> 56 strong interest due 1 6.5 strong interest due
#> 57 algorithms minimal 1 6.5 algorithm minim
#> 58 comparable recall scores 1 6.4 compar recal score
#> 59 multi word keywords 1 6.3 multi word keyword
#> 60 top frequent words 1 6.3 top frequent word
#> 61 score candidate keywords 1 6.3 score candid keyword
#> 62 sample technical abstract 1 6.3 sampl technic abstract
#> 63 stoplists leverage manually 1 6.2 stoplist leverag manual
#> 64 keyword exclusivity exc 1 6.2 keyword exclus exc
#> 65 minimal generating 1 6.1 minim gener
#> 66 supervised learning 1 6.0 supervis learn
#> 67 upper 2 6.0 upper
#> 68 systems candidate keywords 1 6.0 system candid keyword
#> 69 corpus oriented statistics 1 6.0 corpu orient statist
#> 70 member keyword scores 1 5.8 member keyword score
#> 71 text analysis methods 1 5.7 text analysi method
#> 72 word frequency distributions 1 5.7 word frequenc distribut
#> 73 typical function words 1 5.6 typic function word
#> 74 compatibility components 1 5.5 compat compon
#> 75 testing set 1 5.5 test set
#> 76 systems criteria 1 5.4 system criteria
#> 77 manual assignment 1 5.3 manual assign
#> 78 keyword adjacency frequency 1 5.3 keyword adjac frequenc
#> 79 linear 2 5.3 linear
#> 80 content bearing 1 5.0 content bear
#> 81 specific languages 1 5.0 specif languag
#> 82 simple set 1 5.0 simpl set
#> 83 equation 1 4.8 equat
#> 84 text analysis applications 1 4.8 text analysi applic
#> 85 stoplist generation stoplists 1 4.8 stoplist gener stoplist
#> 86 keyword extraction 2 4.8 keyword extract
#> 87 keyword extracts 1 4.8 keyword extract
#> 88 sets solutions 1 4.8 set solut
#> 89 analytic methods 1 4.7 analyt method
#> 90 kyoto protocol 2 4.7 kyoto protocol
#> 91 word ranks 1 4.7 word rank
#> 92 carry meaning 1 4.5 carri mean
#> 93 summary features 1 4.5 summari featur
#> 94 total 1 4.5 total
#> 95 valencia base 1 4.5 valencia base
#> 96 inspec training 1 4.3 inspec train
#> 97 comparable recall 1 4.3 compar recal
#> 98 current state 2 4.2 current state
#> 99 candidate keyword 4 4.2 candid keyword
#> 100 candidate keywords 6 4.2 candid keyword
#> 101 methods inherently 1 4.2 method inher
#> 102 shorter keywords 1 4.2 shorter keyword
#> 103 minimal 5 4.1 minim
#> 104 scores higher 3 4.1 score higher
#> 105 sample abstract 4 4.1 sampl abstract
#> 106 technical abstracts 4 4.1 technic abstract
#> 107 stop word 1 4.0 stop word
#> 108 stop words 5 4.0 stop word
#> 109 actual instances 1 4.0 actual instanc
#> 110 auto matically 1 4.0 auto matic
#> 111 compact representation 1 4.0 compact represent
#> 112 configuration parameters 1 4.0 configur paramet
#> 113 digital libraries 1 4.0 digit librari
#> 114 discriminative fea 1 4.0 discrimin fea
#> 115 effi ciency 1 4.0 effi cienci
#> 116 fixed taxonomy 1 4.0 fix taxonomi
#> 117 future articles 1 4.0 futur articl
#> 118 good choices 1 4.0 good choic
#> 119 google search 1 4.0 googl search
#> 120 hand tuned 1 4.0 hand tune
#> 121 highest values 1 4.0 highest valu
#> 122 highly frequent 2 4.0 highli frequent
#> 123 mark dataset 1 4.0 mark dataset
#> 124 mathematical signatures 1 4.0 mathemat signatur
#> 125 news articles 3 4.0 new articl
#> 126 nical rigor 1 4.0 nical rigor
#> 127 notable difference 1 4.0 notabl differ
#> 128 previous work 1 4.0 previou work
#> 129 professional curators 1 4.0 profession curat
#> 130 scientific literature 1 4.0 scientif literatur
#> 131 search tasks 1 4.0 search task
#> 132 single pass 2 4.0 singl pass
#> 133 standard punctuation 1 4.0 standard punctuat
#> 134 syntactic filters 1 4.0 syntact filter
#> 135 web pages 1 4.0 web page
#> 136 number 4 3.9 number
#> 137 specific subjects 1 3.9 specif subject
#> 138 short abstracts 1 3.9 short abstract
#> 139 function words 1 3.9 function word
#> 140 domain independent 1 3.8 domain independ
#> 141 high recall 1 3.8 high recal
#> 142 inspec corpus 1 3.8 inspec corpu
#> 143 text mining 1 3.8 text mine
#> 144 term frequency 8 3.8 term frequenc
#> 145 term selection 1 3.8 term select
#> 146 score keywords 1 3.8 score keyword
#> 147 score words 1 3.8 score word
#> 148 word scores 1 3.8 word score
#> 149 false positives 1 3.8 fals posit
#> 150 input parameters 2 3.8 input paramet
#> 151 ishizuka state 1 3.8 ishizuka state
#> 152 specific domains 1 3.7 specif domain
#> 153 measure degrades 1 3.7 measur degrad
#> 154 analysis tools 1 3.7 analysi tool
#> 155 protein function 1 3.7 protein function
#> 156 statistical methods 1 3.7 statist method
#> 157 keyword anchors 1 3.7 keyword anchor
#> 158 keyword frequency 1 3.7 keyword frequenc
#> 159 potential keywords 1 3.7 potenti keyword
#> 160 content words 5 3.7 content word
#> 161 contiguous words 1 3.7 contigu word
#> 162 individual words 1 3.7 individu word
#> 163 select words 1 3.7 select word
#> 164 selectively words 1 3.7 select word
#> 165 single words 2 3.7 singl word
#> 166 word delimiters 2 3.7 word delimit
#> 167 benchmark evaluation 2 3.7 benchmark evalu
#> 168 climate change 2 3.7 climat chang
#> 169 computationally efficient 1 3.7 computation effici
#> 170 extremely efficient 1 3.7 extrem effici
#> 171 phrase delimiters 3 3.7 phrase delimit
#> 172 abstract text 1 3.7 abstract text
#> 173 typical abstract 1 3.6 typic abstract
#> 174 criteria 1 3.6 criteria
#> 175 diophantine 2 3.6 diophantin
#> 176 abstracts keywords 1 3.6 abstract keyword
#> 177 occurrence graph 1 3.5 occurr graph
#> 178 primary document’ 1 3.5 primari document’
#> 179 representative list 1 3.5 repres list
#> 180 search results 1 3.5 search result
#> 181 tarau report 1 3.5 tarau report
#> 182 uncontrolled key 1 3.5 uncontrol kei
#> 183 frequent terms 1 3.4 frequent term
#> 184 document frequency 2 3.4 document frequenc
#> 185 document increases 1 3.4 document increas
#> 186 individual documents 4 3.4 individu document
#> 187 large documents 1 3.4 larg document
#> 188 page document 1 3.4 page document
#> 189 single document 1 3.4 singl document
#> 190 multiple words 1 3.4 multipl word
#> 191 word positions 1 3.4 word posit
#> 192 essential content 1 3.4 essenti content
#> 193 essential ity 1 3.4 essenti iti
#> 194 higher precision 1 3.4 higher precis
#> 195 highest precision 1 3.4 highest precis
#> 196 index vocabulary 1 3.4 index vocabulari
#> 197 mixed types 1 3.4 mix type
#> 198 perfect precision 1 3.4 perfect precis
#> 199 professional indexer 1 3.4 profession index
#> 200 stoplist generation 1 3.4 stoplist gener
#> 201 worst stoplist 1 3.4 worst stoplist
#> 202 keywords frequently 1 3.3 keyword frequent
#> 203 metric scores 1 3.3 metric score
#> 204 pos tags 2 3.3 po tag
#> 205 vast collections 1 3.3 vast collect
#> 206 wide range 1 3.3 wide rang
#> 207 manual annotations 1 3.3 manual annot
#> 208 text analyses 1 3.3 text analys
#> 209 text stream 1 3.3 text stream
#> 210 keyword adjacency 3 3.3 keyword adjac
#> 211 words adjacent 1 3.3 word adjac
#> 212 positive results 1 3.2 posit result
#> 213 precision recall 1 3.2 precis recal
#> 214 document text 4 3.2 document text
#> 215 compatibility 2 3.2 compat
#> 216 textrank increases 1 3.2 textrank increas
#> 217 word associations 1 3.2 word associ
#> 218 word list 1 3.2 word list
#> 219 noun phrase 1 3.2 noun phrase
#> 220 performance advantage 1 3.2 perform advantag
#> 221 multiple types 1 3.1 multipl type
#> 222 input stoplist 1 3.1 input stoplist
#> 223 extraction 2 3.1 extract
#> 224 measure rake 1 3.0 measur rake
#> 225 information retrieval 1 3.0 inform retriev
#> 226 multiple corpora 1 3.0 multipl corpora
#> 227 present results 1 3.0 present result
#> 228 rake performance 1 3.0 rake perform
#> 229 set 11 3.0 set
#> 230 sets 1 3.0 set
#> 231 keyword edf 1 2.9 keyword edf
#> 232 dynamic collections 1 2.8 dynam collect
#> 233 ideal application 1 2.8 ideal applic
#> 234 stoplist rake 1 2.7 stoplist rake
#> 235 rake effectively 1 2.7 rake effect
#> 236 reference corpus 1 2.6 refer corpu
#> 237 languages 1 2.6 languag
#> 238 independent 1 2.5 independ
#> 239 algorithm 3 2.3 algorithm
#> 240 algorithms 4 2.3 algorithm
#> 241 approach 1 2.3 approach
#> 242 approaches 1 2.3 approach
#> 243 components 1 2.3 compon
#> 244 graph 1 2.3 graph
#> 245 longer 1 2.3 longer
#> 246 functionality 1 2.2 function
#> 247 method 7 2.2 method
#> 248 methods 5 2.2 method
#> 249 protocol 1 2.2 protocol
#> 250 score 2 2.1 score
#> 251 addition 1 2.0 addit
#> 252 articles 1 2.0 articl
#> 253 content 3 2.0 content
#> 254 contexts 2 2.0 context
#> 255 distributions 1 2.0 distribut
#> 256 due 1 2.0 due
#> 257 frequency 2 2.0 frequenc
#> 258 gener 1 2.0 gener
#> 259 general 2 2.0 gener
#> 260 generality 1 2.0 gener
#> 261 member 1 2.0 member
#> 262 research 1 2.0 research
#> 263 tion 1 2.0 tion
#> 264 automatically 6 1.9 automat
#> 265 abstract 2 1.9 abstract
#> 266 abstracts 1 1.9 abstract
#> 267 recall 2 1.8 recal
#> 268 manually 6 1.8 manual
#> 269 solutions 3 1.8 solut
#> 270 text 6 1.8 text
#> 271 texts 1 1.8 text
#> 272 system 8 1.8 system
#> 273 systems 13 1.8 system
#> 274 terms 3 1.8 term
#> 275 inputs 1 1.8 input
#> 276 multiple 1 1.8 multipl
#> 277 position 1 1.8 posit
#> 278 typically 2 1.8 typic
#> 279 measure 5 1.7 measur
#> 280 measurement 1 1.7 measur
#> 281 analysis 4 1.7 analysi
#> 282 keyword 11 1.7 keyword
#> 283 keywords 53 1.7 keyword
#> 284 word 5 1.7 word
#> 285 words 32 1.7 word
#> 286 change 1 1.7 chang
#> 287 efficiency 1 1.7 effici
#> 288 evaluation 1 1.7 evalu
#> 289 frequently 4 1.7 frequent
#> 290 performance 1 1.7 perform
#> 291 phrases 2 1.7 phrase
#> 292 pos 1 1.7 po
#> 293 tags 1 1.7 tag
#> 294 adjacent 5 1.6 adjac
#> 295 advantages 1 1.5 advantag
#> 296 analyses 1 1.5 analys
#> 297 annotation 1 1.5 annot
#> 298 associations 1 1.5 associ
#> 299 document’ 1 1.5 document’
#> 300 dynamically 1 1.5 dynam
#> 301 exclusive 1 1.5 exclus
#> 302 exclusivity 2 1.5 exclus
#> 303 ideally 1 1.5 ideal
#> 304 information 1 1.5 inform
#> 305 interest 3 1.5 interest
#> 306 ishizuka 1 1.5 ishizuka
#> 307 key 1 1.5 kei
#> 308 list 1 1.5 list
#> 309 lists 1 1.5 list
#> 310 nouns 1 1.5 noun
#> 311 presentation 1 1.5 present
#> 312 protein 1 1.5 protein
#> 313 results 3 1.5 result
#> 314 retrieval 1 1.5 retriev
#> 315 statistically 4 1.5 statist
#> 316 streams 1 1.5 stream
#> 317 subjects 1 1.5 subject
#> 318 summary 1 1.5 summari
#> 319 tarau 1 1.5 tarau
#> 320 valencia 1 1.5 valencia
#> 321 corpus 9 1.5 corpu
#> 322 document 9 1.4 document
#> 323 documents 27 1.4 document
#> 324 essential 2 1.4 essenti
#> 325 essentially 1 1.4 essenti
#> 326 indexes 1 1.4 index
#> 327 indexing 2 1.4 index
#> 328 precision 6 1.4 precis
#> 329 types 3 1.4 type
#> 330 stoplist 15 1.4 stoplist
#> 331 stoplists 16 1.4 stoplist
#> 332 application 2 1.3 applic
#> 333 applications 5 1.3 applic
#> 334 collections 4 1.3 collect
#> 335 domain 1 1.3 domain
#> 336 domains 3 1.3 domain
#> 337 effectively 1 1.3 effect
#> 338 effectiveness 1 1.3 effect
#> 339 widely 2 1.3 wide
#> 340 rake 20 1.3 rake
#> 341 corpora 3 1.2 corpora
#> 342 edf 3 1.2 edf
#> 343 metric 1 1.2 metric
#> 344 metrics 2 1.2 metric
#> 345 textrank 4 1.2 textrank
#> 346 occurrence 1 1.2 occurr
#> 347 occurrences 4 1.2 occurr
#> 348 refer 1 1.2 refer
#> 349 reference 1 1.2 refer
#> 350 references 2 1.2 refer
#> 351 referring 1 1.2 refer
#> 352 ability 2 1.0 abil
#> 353 absence 1 1.0 absenc
#> 354 abstract’ 1 1.0 abstract’
#> 355 adaptive 1 1.0 adapt
#> 356 adjectives 1 1.0 adject
#> 357 adjoin 1 1.0 adjoin
#> 358 aid 1 1.0 aid
#> 359 andrade 2 1.0 andrad
#> 360 arbitrarily 1 1.0 arbitrarili
#> 361 array 2 1.0 arrai
#> 362 art 1 1.0 art
#> 363 authors 2 1.0 author
#> 364 axis 1 1.0 axi
#> 365 bench 1 1.0 bench
#> 366 berry 1 1.0 berri
#> 367 bias 1 1.0 bia
#> 368 biases 1 1.0 bias
#> 369 bold 1 1.0 bold
#> 370 broadly 1 1.0 broadli
#> 371 challenge 1 1.0 challeng
#> 372 chunks 1 1.0 chunk
#> 373 circumstances 1 1.0 circumst
#> 374 clear 1 1.0 clear
#> 375 combination 1 1.0 combin
#> 376 common 1 1.0 common
#> 377 comparison 5 1.0 comparison
#> 378 construction 1 1.0 construct
#> 379 contrast 1 1.0 contrast
#> 380 control 1 1.0 control
#> 381 convergence 1 1.0 converg
#> 382 counts 1 1.0 count
#> 383 creation 2 1.0 creation
#> 384 deg 11 1.0 deg
#> 385 degree 2 1.0 degre
#> 386 desire 1 1.0 desir
#> 387 details 1 1.0 detail
#> 388 discrepancies 1 1.0 discrep
#> 389 drawbacks 1 1.0 drawback
#> 390 drop 1 1.0 drop
#> 391 early 1 1.0 earli
#> 392 easily 2 1.0 easili
#> 393 easy 1 1.0 easi
#> 394 engel 1 1.0 engel
#> 395 envision 1 1.0 envis
#> 396 evident 1 1.0 evid
#> 397 evil 1 1.0 evil
#> 398 expectation 1 1.0 expect
#> 399 finally 2 1.0 final
#> 400 form 1 1.0 form
#> 401 fox 1 1.0 fox
#> 402 fox’ 1 1.0 fox’
#> 403 frees 1 1.0 free
#> 404 freq 9 1.0 freq
#> 405 gle 1 1.0 gle
#> 406 grams 1 1.0 gram
#> 407 greater 1 1.0 greater
#> 408 gutwin 1 1.0 gutwin
#> 409 hulth 2 1.0 hulth
#> 410 hyperlinks 1 1.0 hyperlink
#> 411 implementations 1 1.0 implement
#> 412 inaccessible 1 1.0 inaccess
#> 413 introduction 1 1.0 introduct
#> 414 intuition 1 1.0 intuit
#> 415 iterations 1 1.0 iter
#> 416 jones 2 1.0 jone
#> 417 judgment 1 1.0 judgment
#> 418 kee 1 1.0 kee
#> 419 keyphind 1 1.0 keyphind
#> 420 lack 1 1.0 lack
#> 421 limits 1 1.0 limit
#> 422 manner 1 1.0 manner
#> 423 material 1 1.0 materi
#> 424 matsuo 2 1.0 matsuo
#> 425 meaningful 2 1.0 meaning
#> 426 meaningless 1 1.0 meaningless
#> 427 michael 1 1.0 michael
#> 428 mihal 1 1.0 mihal
#> 429 mihalcea 1 1.0 mihalcea
#> 430 miss 1 1.0 miss
#> 431 motivation 1 1.0 motiv
#> 432 observation 1 1.0 observ
#> 433 occur 1 1.0 occur
#> 434 order 4 1.0 order
#> 435 pairs 1 1.0 pair
#> 436 part 1 1.0 part
#> 437 paynter 1 1.0 paynter
#> 438 phrasier 1 1.0 phrasier
#> 439 practice 1 1.0 practic
#> 440 predominantly 1 1.0 predominantli
#> 441 primarily 2 1.0 primarili
#> 442 purposes 2 1.0 purpos
#> 443 queries 1 1.0 queri
#> 444 quickly 1 1.0 quickli
#> 445 rake’ 2 1.0 rake’
#> 446 rarely 1 1.0 rare
#> 447 rate 1 1.0 rate
#> 448 ratio 1 1.0 ratio
#> 449 rdf 4 1.0 rdf
#> 450 reasoning 1 1.0 reason
#> 451 relationship 1 1.0 relationship
#> 452 reliable 1 1.0 reliabl
#> 453 remarkably 1 1.0 remark
#> 454 resources 1 1.0 resourc
#> 455 risk 1 1.0 risk
#> 456 runs 1 1.0 run
#> 457 salton 1 1.0 salton
#> 458 section 1 1.0 section
#> 459 sections 1 1.0 section
#> 460 sentences 1 1.0 sentenc
#> 461 sequence 2 1.0 sequenc
#> 462 sequences 2 1.0 sequenc
#> 463 series 1 1.0 seri
#> 464 share 1 1.0 share
#> 465 significance 1 1.0 signific
#> 466 simplicity 2 1.0 simplic
#> 467 small 1 1.0 small
#> 468 solely 1 1.0 sole
#> 469 speech 1 1.0 speech
#> 470 style 1 1.0 style
#> 471 subset 3 1.0 subset
#> 472 suitable 1 1.0 suitabl
#> 473 sum 2 1.0 sum
#> 474 sys 1 1.0 sy
#> 475 tech 1 1.0 tech
#> 476 techniques 2 1.0 techniqu
#> 477 tems 1 1.0 tem
#> 478 theory 1 1.0 theori
#> 479 time 3 1.0 time
#> 480 times 1 1.0 time
#> 481 title 1 1.0 titl
#> 482 topic 1 1.0 topic
#> 483 tures 1 1.0 ture
#> 484 uninformative 1 1.0 uninform
#> 485 unique 1 1.0 uniqu
#> 486 unsupervised 1 1.0 unsupervis
#> 487 user 1 1.0 user
#> 488 users 2 1.0 user
#> 489 utility 1 1.0 util
#> 490 variability 1 1.0 variabl
#> 491 variety 1 1.0 varieti
#> 492 volume 1 1.0 volum
#> 493 whitney 1 1.0 whitnei
#> 494 window 2 1.0 window